 Grant Novota
Grant NovotaFile Fetching App
Project Overview
The goal of this project was to demonstrate backend architecture design skills, write some of the relevant code, and explain the next steps in continuing the implementation.
Requirements
- The system shall consist of a fetching application, a database, an optional persistent volume, and a set of verification applications.
- The fetching application shall be able to download text files over HTTPS at a regular interval.
- Users shall be able to change the interval at which each file is fetched.
- Users shall be able to add new URLs and disable existing ones.
- The fetching application shall keep a copy of all the new versions of the file, even if the filename has not changed.
- The verification applications shall be able to ingest one of those text files and certify that the file has passed or failed verification.
- Users shall be able to know whether a file has passed verification.
- The verification applications shall be started upon successful fetch of a file or set of files.
- The overall system shall log all actions it has taken.
Assumptions
- A CI/CD system will be used for deployment and management of the system, and may be used for some configuration.
- No URL will need to be fetched more than once per hour. This isn’t a high speed polling system.
- More applications may be added to the system than the ones described above.
Architecture Summary
For this system, I chose to use a CentOS 8 container (could also use a VM). CentOS is popular with system admins, used by many organizations for development and production servers, and is an OS that I am familiar with using for this type of project. The system contains a SQL database that stores information on the urls to be fetched and all the files that have been stored. The database is set up and modified through a python script (db.py). A python fetching app (fetch.py) is run hourly by a cron job and gathers URLs to be fetched by checking if they are enabled and if their fetching interval is in line with the current hour. It also checks if the file source has been modified since the last time it was downloaded and will download the new version if so. The file will be placed in a storage pool (I would use a ZFS file system for organization and scalability). Once a file is fetched, the fetching app triggers the verification apps via their API. These verification apps could be present within the container or running in a separate container/VM. A user may interact with this system by modifying values in the database. This could be done via SSH in a CLI or a web app. Below is a high-level block diagram of the system:
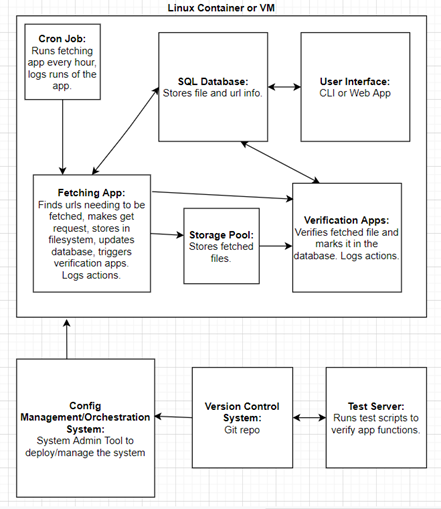
CI/CD
The system will use a git repository for development, and it will be connected to a test server to check the developer’s commits to the repository. A system admin tool (SaltStack, Puppet, or whatever is already in place) will be used to deploy and orchestrate the system by pulling from the git repo, running setup commands, and maintaining the state of the machine that is running the system.
Database
The system uses a sqlite database with two tables: File and URL. The users and apps change behavior of the system via the database and they can do so via the Python interface (db.py), which uses ORM.
- File
- Id - autoincremented identifier
- Name - file name
- url - ID of the associated URL, could be multiple files linked to same URL
- Path - file path in storage
- Last modified - time that the source was last modified
- Verified - status of verification by the verification apps
- URL
- Id - autoincremented identifier
- Address - full URL
- Enabled - indicates if URL should be fetched
- Last fetched - when the URL was last fetched
- Interval - how often URL should be fetched
Logging
The cron job will log its hourly runs of the fetching app, the fetching app will log the actions it has taken through the use of the Python logging package, the ZFS storage pool maintains its own log, and the user interface will log user actions.
Fetching App:
The fetching app is a python script (fetch.py) that is run hourly by a cron job in the CentOS 8 system. It first gathers enabled urls from the database that have an interval indicating that the url should be fetched during the current run. It then makes a GET request to the url and checks if the source file has been modified since the last time the file was downloaded. If this is the case, the fetching app will store the new version of the file in the storage pool and call upon the verification apps before moving on to the next url to fetch. The verification apps will interact with the database directly to indicate if a file has been verified or not.
User Interface
Users may interact with the system by modifying values in the database to do things like add/enable/disable a url and check if a file has passed verification. This can be done using the db.py script via the command line. Another option for this would be to set up a web interface that makes API calls to the database. I would build a python web app using flask or django (django handles user auth better) and service it with an Nginx reverse proxy.
Current state of the project
I have built a Centos 8 container setup using a dockerfile, which builds the database, sets up a cron job, and includes a basic fetching script for storing files and placing them in a folder. I would expand this to use a ZFS storage pool that can be mounted and binded to the docker container. I have also built a CLI for building, viewing, and modifying the database through the db.py script. The project needs a CI/CD system built around it as well as a pipeline for all of the activity logs that would be generated by various components of the system. Furthermore, a more complex user interface needs to be developed to allow access to the values stored in the database and the files that have been downloaded. The project can be built using the docker build command and once it is running, you can interact with the database by SSHing into the container and using the CLI commands. Setup and database interaction commands are listed in README.md. I built and ran the project within a Centos 8 VM.
Building/Running/Interacting with the code
Components
- Fetching app - fetch.py
- Database app - db.py
- Package requirements file - requirements.txt
- Cronjob file - fetch-cron
- Docker file - Dockerfile
- Setup script - setup.sh
Setup
run docker build .
find container id with docker images -a
start the container with docker run --name NAME ID#
login to the interactive shell of the container docker exec -it NAME/ID bash
The container uses an hourly cronjob that runs fetch.py outputs to the docker stderr and stdout.
To check if the job is scheduled
docker exec -ti <your-container-id> bash -c "crontab -l"
To check if the cron service is running
docker exec -ti <your-container-id> bash -c "pgrep cron"
stop the container with docker stop NAME/ID
Database Functions
- Build database:
$ python3 db.py build_db - Print all database items
$ python3 db.py dump - Add url to fetch:
$ python3 db.py add_url ADDRESS INTERVAL- supports whole number invervals in hours or days (1h) or (1d) - Modify url fetch interval
$ python3 db.py set_interval ADDRESS INTERVAL - Enable/Disable url
$ python3 db.py url_enabled ADDRESS True/False
Project Repo: https://github.com/Novota15/Backend-System-Draft